
Jako vývojáři, business analytici nebo softwaroví architekti se často pohybujeme v doménách, které jsou pro nás nové a které neznáme. Nejprve tedy potřebujeme identifikovat, co naši budoucí uživatelé skutečně potřebují, s jakými problémy se potýkají a co přinese businessu největší hodnotu.
To se ale ne vždy děje. Snadno sklouzáváme k technickým řešením, protože na to jsme odborníci. Vystačíme si jen s povrchním pochopením problematiky. Stačí nám základní zadání a zbytek si ochotně domyslíme. DDD ale vyžaduje víc, totiž týmovou práci. Ano, sami sice dokážeme vymyslet technická řešení, ale oni zase znají business. My se přes noc nenaučíme, co vše obnáší jejich práce, a oni zase přes noc nepřičichnou k té naší. Jedině společně tedy můžeme postavit solidní základy nového systému.
Jak začít?
Když se poprvé sejdeme s doménovým expertem, tak nevíme, které informace jsou důležité nebo kde vůbec začít. Učíme se základní pojmy a objevujeme klíčové koncepty. V hlavě se nám postupně rodí mentální model zachycující naše aktuální chápání věcí. Dalším krokem je vizualizace tohoto modelu. K tomu můžeme využít kresby, UML diagramy nebo libovolnou jinou formu, která bude srozumitelná i pro netechnické lidi.
Jak by to mohlo vypadat, si ukážeme na příkladu implementace systému pro logistickou společnost. Doménový expert řekne, že se zabývají převozem zásilek mezi pobočkami. Zásilku od zákazníka převezmou na podatelně, odkud následně putuje na výdejnu. Tam si ji může vyzvednout kdokoliv, kdo se prokáže výdejním kódem.
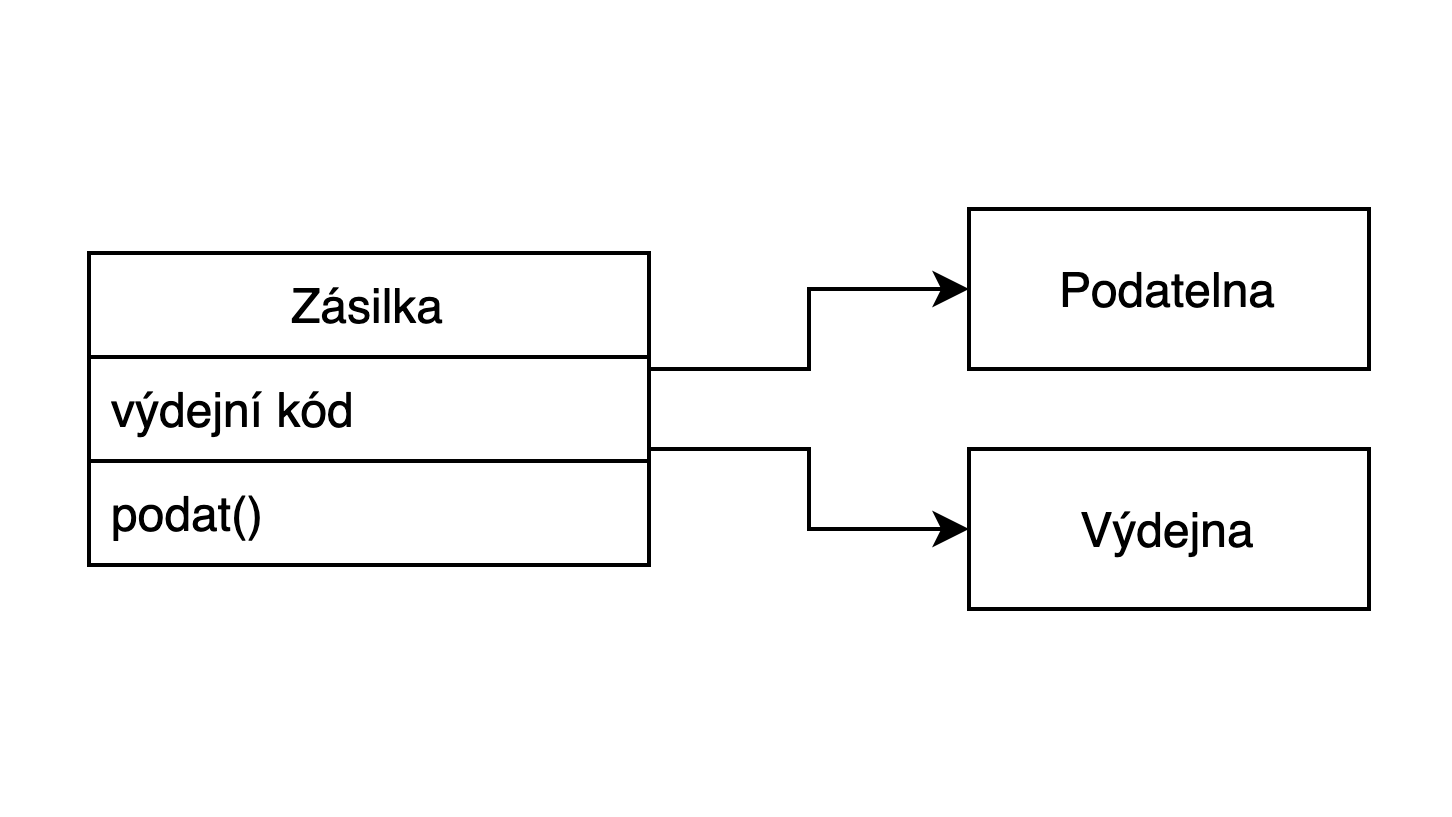
Jakmile máme hotovo, je vhodné se znovu sejít s doménovým expertem a ověřit si s ním správnost modelu. Prvotní model nebude správně. A nejspíš nebude správně ani jeho druhá verze. To je očekávatelné a do jisté míry také nevyhnutelné. Modelování je iterativní proces a s každou další iterací prohlubujeme své vědomosti a model zpřesňujeme.
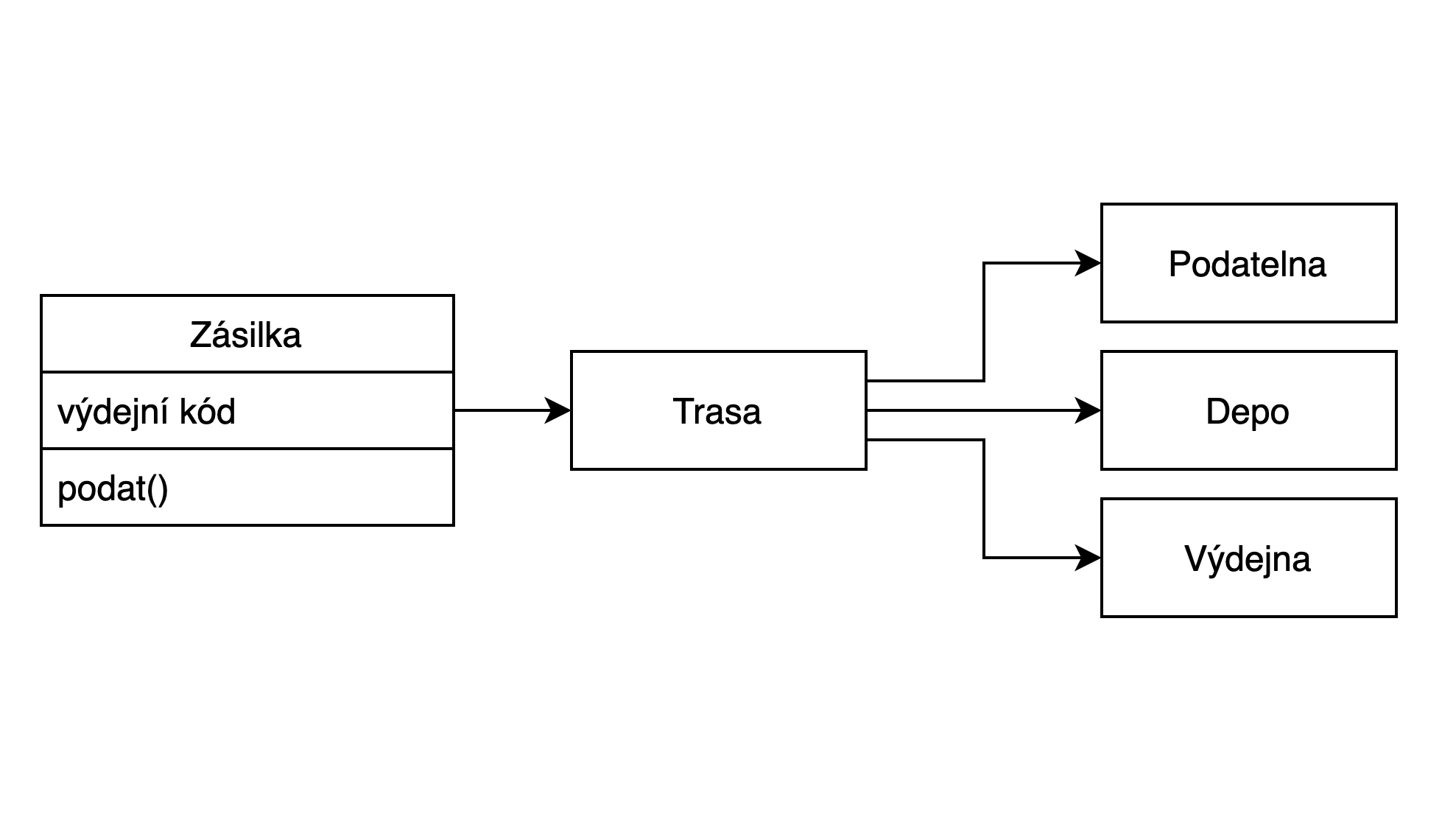
Na druhé schůzce se například dozvíme, že zásilka z podatelny nejede přímo na výdejnu. Zásilky se pohybují podle předem definovaných tras. Typicky se sváží na depo a až z něj putují do výdejen.
Model musí být užitečný
Neexistuje jen jeden „správný“ model dané domény. Při modelování se snažíme vytvořit takovou abstrakci, která bude užitečná pro řešení našeho problému. Všechny nepodstatné aspekty můžeme vynechat. Cílem není modelovat reálný svět ani vymýšlet obecná řešení. Žádný model není obecně užitečný, vždy záleží na kontextu.
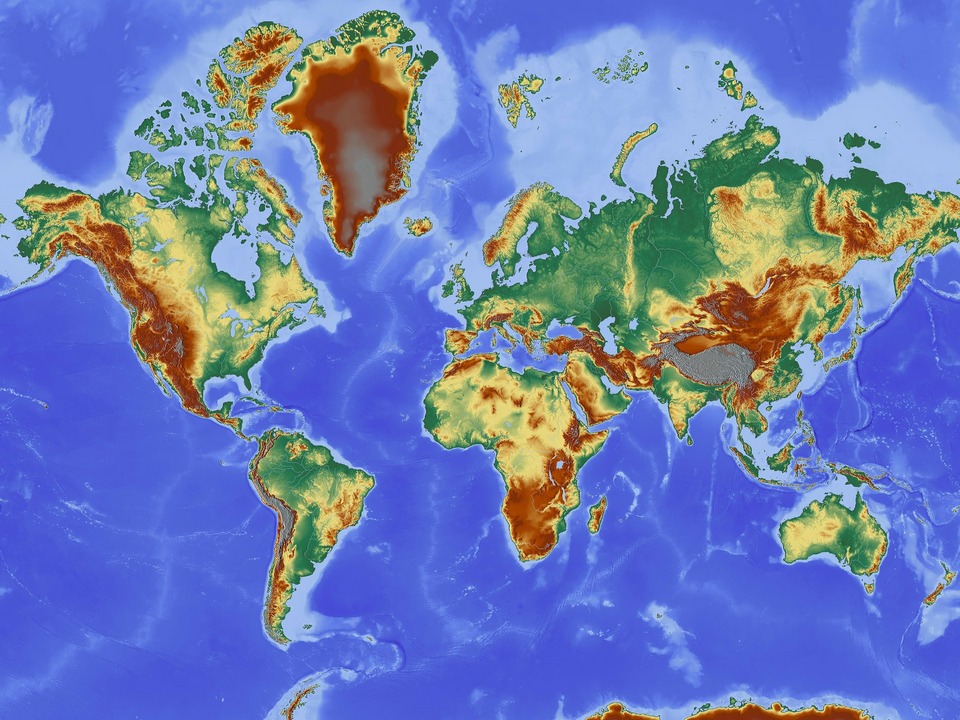
Na obrázku vidíte model Země reprezentovaný mapou, která se běžně používá při výuce dětí. Porovnáním velikosti Afriky a Grónska můžeme nabýt dojmu, že mají přibližně stejnou rozlohu. Ve skutečnosti to ale není pravda, protože Afrika je 14x větší než Grónsko. Proč jsou tedy na mapě stejně veliké? Je to proto, že se jedná o Mercatorovo zobrazení, které má tu vlastnost, že směr mezi libovolnými dvěma body na mapě odpovídá jejich skutečné vzájemné orientaci. To se v minulosti hodilo námořníkům, kteří podle mapy snadno určili směr, jímž mají plout. Pro porovnání rozlohy jsou však vhodné jiné modely.
Kód vyjadřuje model explicitně
Vývojáři zvyklí pracovat s relačními databázemi často používají pojmy jako create, update nebo delete. Takové pojmy se v doménách ale typicky nevyskytují. Zákazník zásilku nevytváří, ale podává. Podanou zásilku nemažeme, ale stornujeme. Může to znít jako drobný rozdíl, ale je důležitý. Výsledný software by totiž měl explicitně vyjadřovat doménový model.
Dnes jsme se naučili 3 důležité zásady tykající se doménového modelu. Tou první je, že modelování probíhá v iteracích, do kterých musíme zapojit doménového experta. Následuje pravidlo, že model musí být užitečný při řešení našeho problému. Poslední zásada se pak týká nutnosti model explicitně vyjádřit v implementaci.
Citace:
Eric Evans. Tackling Complexity in the Heart of Software. Brusel. DDD Europe 2016.
Sdílet článek